Churn, eller mistede kunder, er noget alle virksomheder er interesserede i at forhindre. Det koster nemlig mellem fem og femogtyve gange mere at skaffe nye kunder end at fastholde eksisterende kunder. Kilde (Harvard Business Review).
Helt enkelt beregnes churn ved at dividere antallet af kunder, der har opsagt deres abonnement eller er stoppet med at købe produkter inden for en given tidsperiode, med antallet af aktive kunder i begyndelsen af samme tidsperiode. Denne enkle analyse giver stor værdi, da den kan bruges som benchmark, når man sammenligner betydningen af mere avancerede prædiktive modeller. På den måde kan man finde ud af hvordan churn-niveauet ændrer sig over tid, og hvordan produktgrupper kan bruges til at fokusere på bestemte kundesegmenter. I denne artikel går vi endnu dybere og taler om prædiktiv churn-analyse, der giver endnu større værdi.
Prædikativ churn-analyse
Churn skal som regel nedbrydes på et mere detaljeret niveau, da kunderne varierer i adfærd og præferencer, hvilket afspejler sig i, hvor tilfredse de er, eller hvor stor lysten er til at skifte til en konkurrent. Det er her en prædikativ churn-analyse kan bruges.
Sandsynligheden for churn kan beregnes ud fra flere statistiske metoder eller Machine Learning. Metoderne behandler historisk kundeaktivitet og adfærdsdata for at beregne sandsynligheden for churn pr. kunde.
Hvor skal man starte?
For at opbygge en vellykket prædiktiv churn-model kræves først og fremmest en klar use case. Ikke kun for at afgøre, hvem der skal bruge modellens resultater og hvorfor, men også for at hjælpe data scientists med at vælge metoder.
Anvendelsesområder
- Oprette Churn Risk Scorecards, der kan indikere, hvem der sandsynligvis er på vej væk, og bruge disse oplysninger i fastholdelseskampagner
- Forudsige sandsynligheden for churn og bruge resultaterne til at markere kunder til fremtidige e-mail-kampagner
- Integrere churn-modellens resultater med interne applikationer, som kundeservice bruger, til at dele churn-resultater med kundeservice, og kundeservice indsamler kundeadfærd til churn-modellen.
- Mere om anvendelsesområder i denne artikel, 7 fordele ved en churn-analyse.
Kundedata
Da en churn-analyse er baseret på statistik og historik, er en churn-analyse ikke egnet til startups, der endnu ikke har fået opbygget kundevolumen, men derimod til mellemstore og store virksomheder, der har været på markedet i et par år.
Udførelse
1. Eksporter data
Det første skridt er at eksportere historiske kundedata fra kundeservice som et datasæt. Kundedata ligger ofte i et CRM-system eller i en database fra et Data Warehouse, hvor hver unik kunde har et kundenummer.
2. Forbered datasættet til analyse
Det er almindeligt, at kundedata findes forskellige steder og derfor skal hentes fra forskellige datasystemer og sættes sammen. Dette gøres som regel i Excel eller SQL. Datasættet kan mangle værdier, have forkerte værdier eller have blandede datatyper, så datasættet skal vaskes og struktureres, før det kan bruges til churn-analyse.
Tabel 1: Eksempel på datasæt.
| Kundenummer | Churn | Køn | Alder | Antal månader som kunde | Produktgruppe |
| 10001 | Nej | Mand | 23 | 14 | Stor |
| 12001 | JA | Kvinne | 38 | 5 | Mellen |
| 10021 | Nej | Mand | 56 | 43 | Lille |
3. Vælg værktøj til churn-analyse
Der findes flere værktøjer til churn-analyse på markedet. Fra mere grafiske grænseflader som Microsoft Machine Learning Studio og Alteryx Designer til mere script-baserede værktøjer som Python og R-Studio.
4. Vælg metode til churn-analyse
En churn-analyse kan foretages ved hjælp af forskellige statistiske metoder som f.eks. algoritmerne Logistisk regression, Random Forest eller Gradient Boosting. Præsenter din use case for data scientists eller konsulenter inden for avanceret analysekonsulenter for at diskutere, hvilke metoder der skal bruges.
Tips! Test flere forskellige statistiske metoder for at kunne sammenligne modeller og resultater.
5. Træn og test modellen
Opdel dit datasæt i et subdatasæt for at træne din model og et andet subdatasæt for at teste din model og validere den mod nye data, der ikke bruges til at træne modellen. En almindelig fordeling er, at 80 procent af rækkerne bruges til at træne modellen og de resterende 20 procent bruges til at teste modellen. Fordelingen skal ske tilfældigt. Byg en model, som du træner ved hjælp af dit datasæt. I din model, som du kan bygge i Machine Learning Studio eller Alteryx, vælger du statistiske metoder, som du kan sammenligne med hinanden. Brug gerne hjælp fra en data scientist eller BI-konsulent, når du bygger din model.
6. Fortolk resultatet og kør modellen igen
Du kan ofte få resultatet fra din model ud som en ROC-kurve, hvor man ønsker at opnå en høj True-Positive rate og en lav False-positive rate.
Figur 1: ROC-kurve, Kilde: Towards data science.
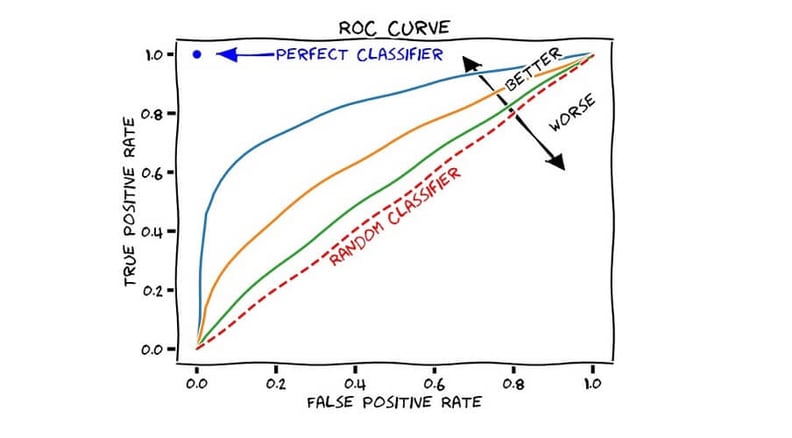
Figur 1:ROC-kurva, Källa Towards data science.
Rådgivning før din første churn-analyse
Er du interesseret i at komme i gang med churn-analyse? Du er velkommen til at kontakte os hos Random Forest, så kan vi fortælle dig mere om Machine Learning Studio eller Alteryx, og hvad du skal tænke på i forbindelse med dit datasæt og den model, du skal bygge.
Joakim Rydén SjöstrandJoakim Rydén Sjöstrand arbejder som Business Intelligence-konsult i Random Forest. Han har arbejdet med at udføre Business Intelligence-løsninger og har også mangeårig erfaring som forretningsanalytikere. |


